
Infra Breakdown: Explaining the Stack, One Layer at a Time
An Introduction to the Software Powering Modern Applications

The Invisible Layer of the AI and Software Economy
When I first started recruiting for venture roles ~2 years ago, infrastructure software felt like a daunting black box. Over the past couple of years I’ve learned a lot, but there’s still plenty I’m figuring out — which is why I’m starting this series.
Infra Breakdown is my attempt to deconstruct the different layers of the infrastructure stack, aiming to (i) crystalize my own perspective and (ii) hopefully share a few helpful insights with you along the way.
For those less familiar with the space, many of today’s most valuable companies aren’t building the consumer applications we use daily (like Airbnb or Netflix). Instead, they are building the fundamental pipes and platforms that those applications run on.
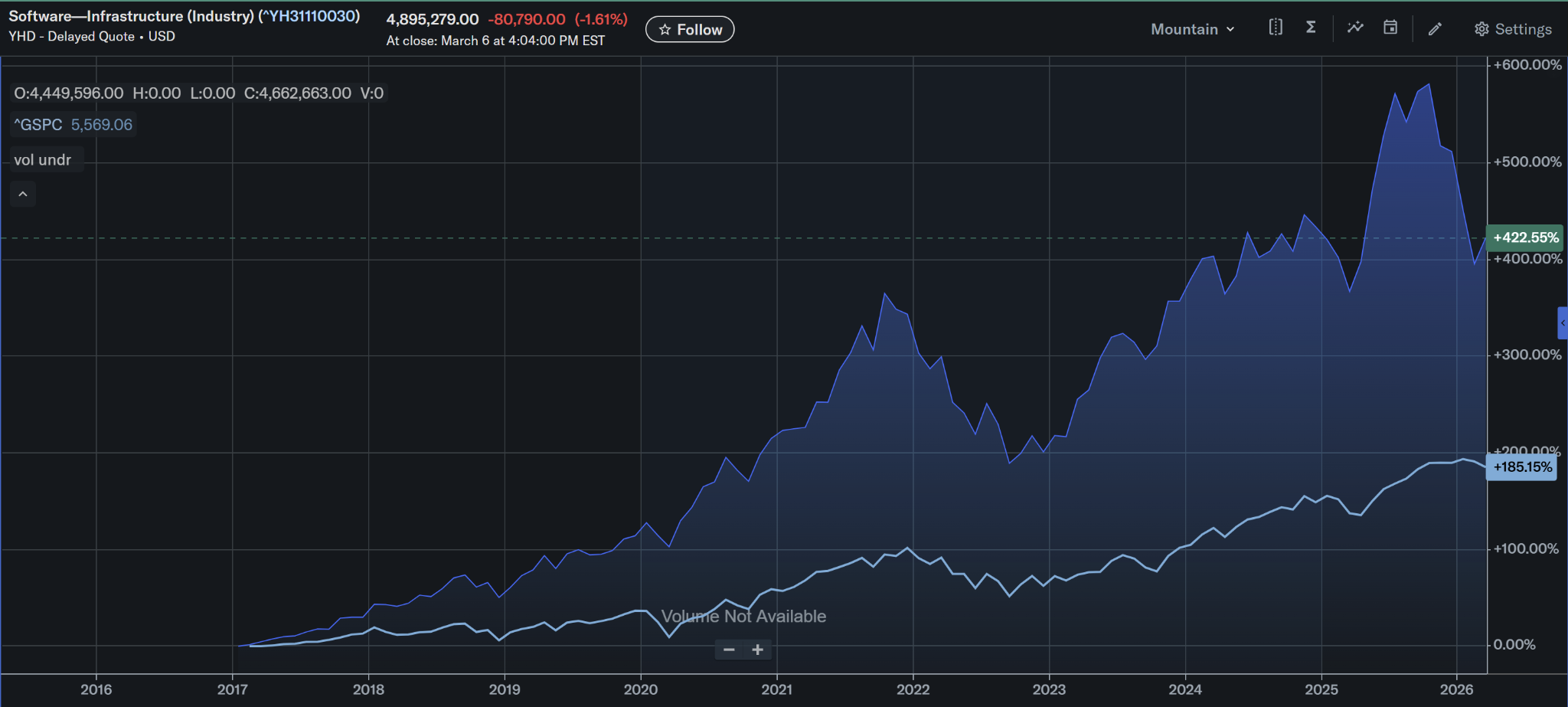
The scale of this sector is often underestimated. In fact, the public market value of infrastructure software assets is roughly 3x that of application software – currently valued at $4.9T on $590B of total revenue (hopefully a bit higher by the time you read this… unless SaaSpocalypse has its way).
To put it in perspective, there are many companies that sit underneath the visible software economy: Databricks powers data pipelines, Snowflake runs analytics workloads, Supabase runs application backends, Stripe runs payments… the list goes on.
These are the “picks and shovels” that enable millions of other products to exist. Yet, despite powering huge portions of the internet, infrastructure remains one of the least understood parts of the technology stack.
This series aims to break it down, layer by layer.
Why Infrastructure Software Matters Now More Than Ever
Three structural shifts are expanding the importance of infrastructure software.
Application / software creation is accelerating: AI tools, low-code platforms, and developer frameworks (from the Lovable / Claude Code’s of the world to platforms like Canva) are dramatically lowering the cost of building software. The number of applications being created is exploding – 72% of developers who have tried AI use it every day; GitHub reported ~986M commits (+25% y/y)
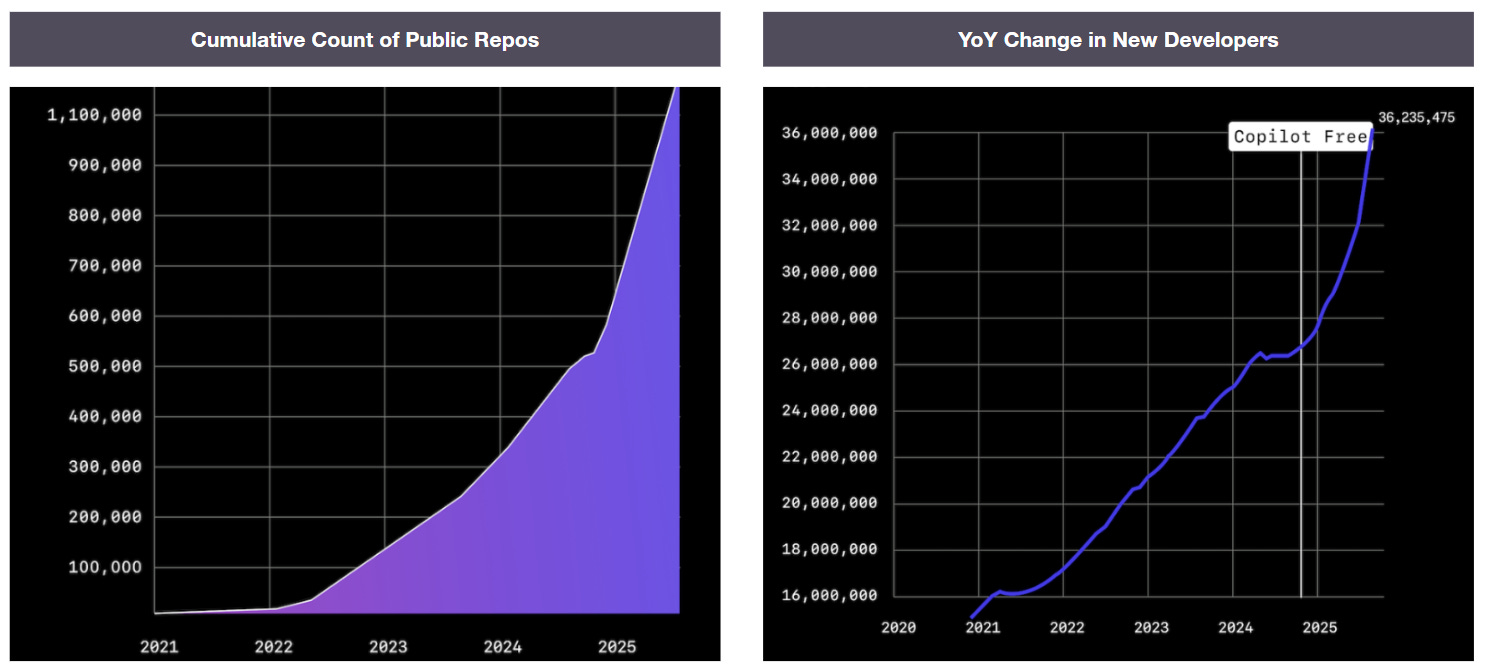
Developers no longer build everything themselves: A decade ago, building an application required provisioning servers, managing databases, setting up authentication, and operating infrastructure. Today, developers increasingly assemble products from managed services (e.g., Supabase, Neon, etc.).
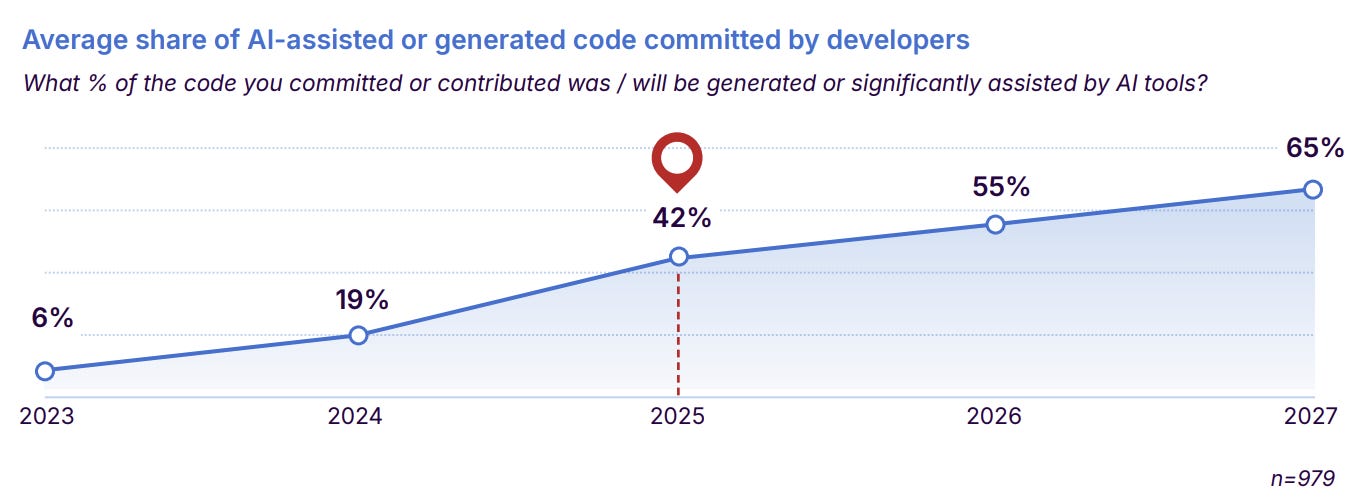
Infrastructure platforms capture compounding value: The companies providing these foundational layers benefit from powerful dynamics: Every new app increases demand for infrastructure → Developer ecosystems compound over time → Switching costs rise as systems scale.
This is why infrastructure software companies frequently become some of the most valuable companies in technology.
The Evolution of the Infrastructure Stack
Most modern software systems are often described as a layered stack. A few years ago, this idea was popularized as the “modern data stack” thesis: a clean set of modular layers where each company owned a specific function (fun Reddit thread on the rise and fall of the modern data stack).
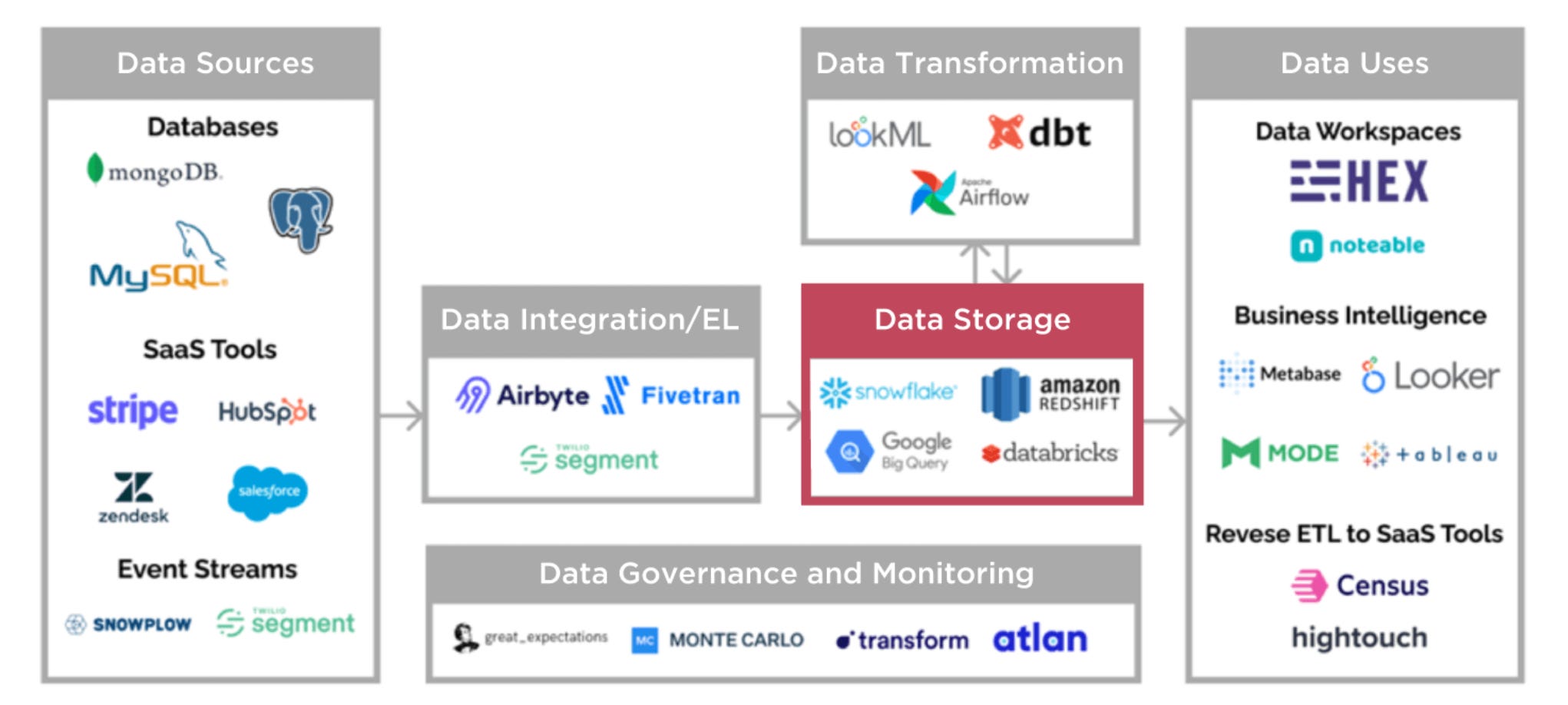
The logic behind this framing was fair: software infrastructure should behave like Lego blocks (i.e., cloud data warehouses + SaaS tooling replacing monolithic platforms) – teams could assemble best-of-breed tools at each layer, and startups could win by owning a single, well-defined layer of the stack.
From Static Stacks to AI Gravity Wells
In practice, the software market rarely stays neatly layered for long. Microsoft is the classic example of this as they initially found their wedge in infrastructure with Windows (‘80s - ’90s) → expanded into the application layer with Office (‘90s - early ’00s) → and then scaled cloud / developer services with Azure (2010s). And they’ve kept pushing on since with acquisition / expansion of Teams, Dynamic 365, GitHub, etc.
Microsoft didn’t just stay in its lane; it expanded until it owned the entire road.
Instead of thinking about software as a static stack, it is more accurate to view it as a series of platform control planes sitting at critical points in the developer workflow. In the AI era, this transition has accelerated. The “Modern Data Stack” was a useful map for an earlier phase of the ecosystem, but the winners of this next era aren’t just modular layers — they are gravity wells.

In the current AI infrastructure landscape, the stack is collapsing into consolidated power centers:
The Model as the Operating System: We are seeing a pivot where the LLM is no longer just a component; it is becoming the central orchestrator for compute, memory, and logic.
Workflow Integration over Modularity: Enterprises are moving away from “best-of-breed” point solutions (i.e., separate vector DB + separate monitoring tool + separate prompt manager) in favor of integrated platforms that own the end-to-end lifecycle.
The Data Moat: The “gravity” is generated by where the data lives. If a platform owns the context, it eventually owns the application.
The real architecture of the AI era looks less like a ladder and more like a set of overlapping platforms that expand until they dominate the entire developer workflow. To win today isn’t to be a better layer, but moreso becoming the platform that the rest of the ecosystem is forced to orbit.
In this series, we’ll be breaking down the critical points of the AI infrastructure stack.
Next up: Databases.